GreenArrow Cluster
- Table of Contents
- Overview
- Cluster architecture using HAProxy
- Cluster architecture using GreenArrow Proxy
Overview
This page provides a overview of how GreenArrow instances can be clustered together to achieve High Availability and High Scalability, using either ther HAProxy or GreenArrow Proxy.
For more information on using GreenArrow with GreenArrow Proxy, see the following pages:
GreenArrow can be used in a high availability cluster in a variety of ways.
-
Create a group of VMs or bare metal servers, each running GreenArrow or GreenArrow Proxy. Use load balancers in front of the VMs to distribute events and injection to the instances.
-
Use GreenArrow’s Kubernetes Reference Architecture to install GreenArrow in Kubernetes.
-
Assemble your own Kubernetes cluster, using the components provided by GreenArrow as a basis.
GreenArrow is very adaptable to different performance, reliability, and configuration needs. Feel free to reach out to our technical support team to get consultation about how best to install GreenArrow for your needs.
Cluster architecture using HAProxy
Many large ESPs and senders run a fleet of GreenArrow Engine servers that cooperate together to achieve High Availability and High Scalability in a Mail Transfer Agent. The architecture described below does not use GreenArrow’s clustering features. (The next section will describe GreenArrow’s clustering features.)
The architecture is typically as follows:
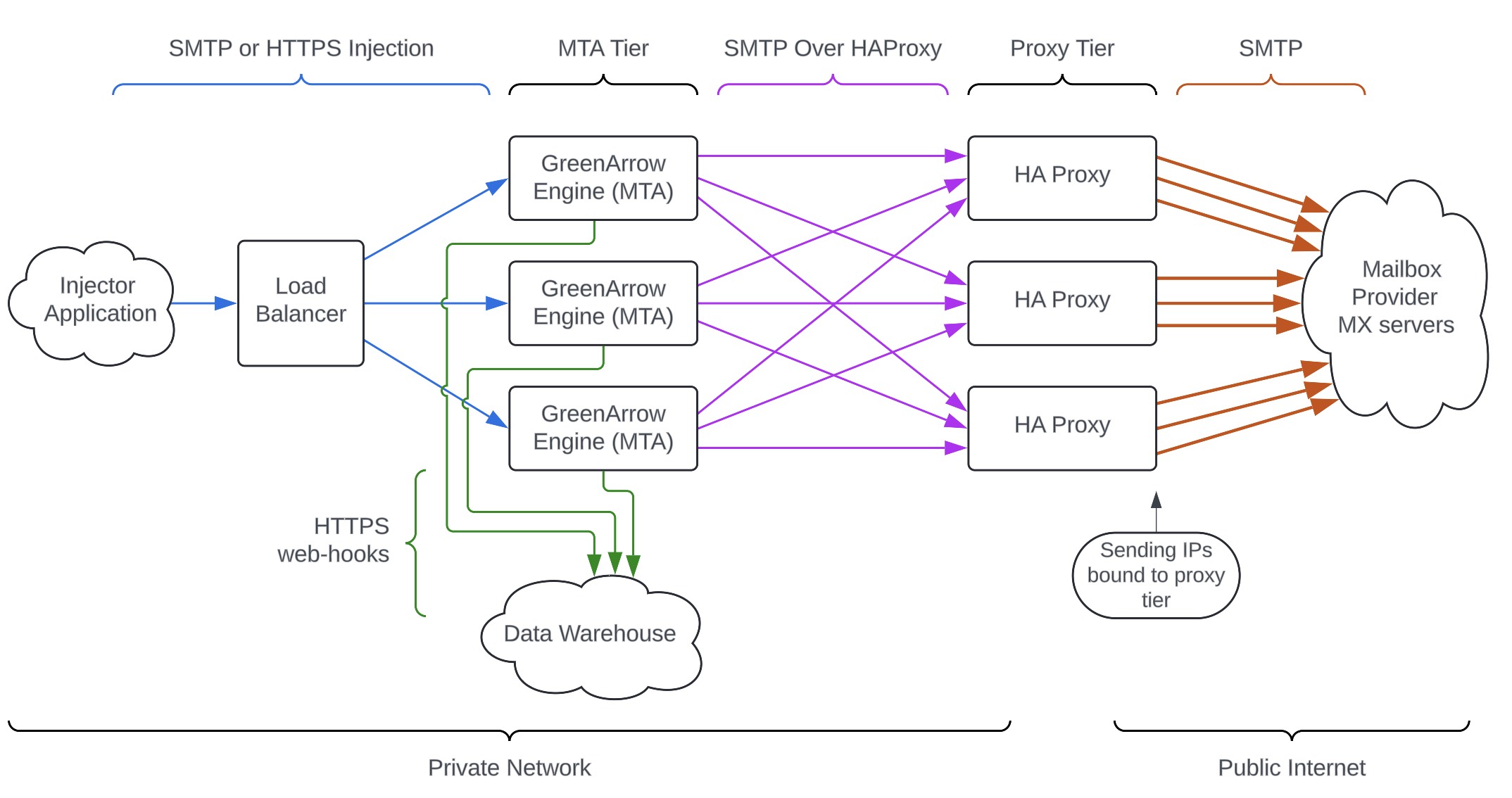
|
Injector Application
This is the application that creates emails that need to be delivered. The application will connect to the Load Balancer to hand-off the emails. |
|
|
Load Balancer
This is a standard load balancer that distributes the email evenly to each MTA in the cluster. This can be an OSI Layer 7 load balancer that operates on the HTTP or HTTPS level, or an OSI layer 4 load balancer that operates on TCP sessions (for either HTTP, HTTPS, SMTP, or SMTPS). Both options work perfectly fine. |
|
|
SMTP or HTTP Injection API
Messages are handed from the Injector Application, through the Load Balancer, into the MTA Tier using either SMTP for injection (typically authorized by username/password instead of IP address) or the GreenArrow HTTP injection API. |
|
|
MTA Tier
Each server is configured with identical configuration of all of the IP addresses, DKIM keys, and domains. Therefore each MTA is able to handle any outgoing message for any sending IP and any tenant. The configuration files are typically stored in a git repository and published out to all MTAs using software like Puppet, so that a push to git triggers a continuous integration process to publish the config to each MTA. The MTAs do not directly originate connections to MX Servers. Instead, they connect to the Proxy Tier using SMTP Over HAProxy and request that HAProxy originate a connection from the Sending IP (which is bound to the HAProxy server) to the appropriate MX Server. Each MTA makes its own independent throttling decisions.
These servers are sized for high network bandwidth, high compute, and high disk IO. A common AWS instance type is |
|
|
Proxy Tier / HAProxy
This is a set of servers running the HAProxy software. Each HAProxy server has a subset of the public Sending IPs bound to it. The purpose of this tier is to allow every MTA to make connections from any Sending IP. If the sending IPs were bound to the MTAs, then each MTA would only be able to establish connections from the sending IPs bound to it. Each HAProxy server also has an IP address on the Private Network, which is used by the MTAs to contact it. These nodes are stateless. These servers are sized for high network bandwidth, but do not require much compute or disk IO. A common AWS instance type is |
|
|
Private Network
The communication between the Injection Application, Load Balancer, MTA, and HAProxy servers are typically done on a private network address space, and firewalled off from the public Internet – although this is not required. |
|
|
HTTPS web-hooks
The MTA servers communicate information on delivery attempts and synchronous bounces (sometimes called “accounting information”) to your Data Warehouse or Data Lake typically using web-hooks over HTTPS. GreenArrow is very flexible in batching event data for high throughput. This can also be done by having GreenArrow write accounting files (such as CSV or SqLite format) and shipping them off the MTA servers, or having the MTA establish a database connection directly to your Data Warehouse and insert rows into a table or run a stored procedure. |
Here is a description of a cluster using this architecture run by Klaviyo.
Cluster architecture using GreenArrow Proxy
A cluster using GreenArrow’s clustering features is similar to the above, but there are some key differences (which are noted in bold in the diagram below using bold)
- The Proxy Tier is running GreenArrow Proxy instead of HAProxy.
- Throttle decisions for each Sending IP are made on the GreenArrow Proxy instance that hosts that Sending IP, instead of independently on each GreenArrow MTA server. This allows for coordinated cluster-wide throttling limits, without introducing a new single-point-of-failure into the system.
- The protocol between the MTA Tier and the Proxy Tier is now the Proprietary GreenArrow Proxy Protocol. This protocol has certain advantages described below.
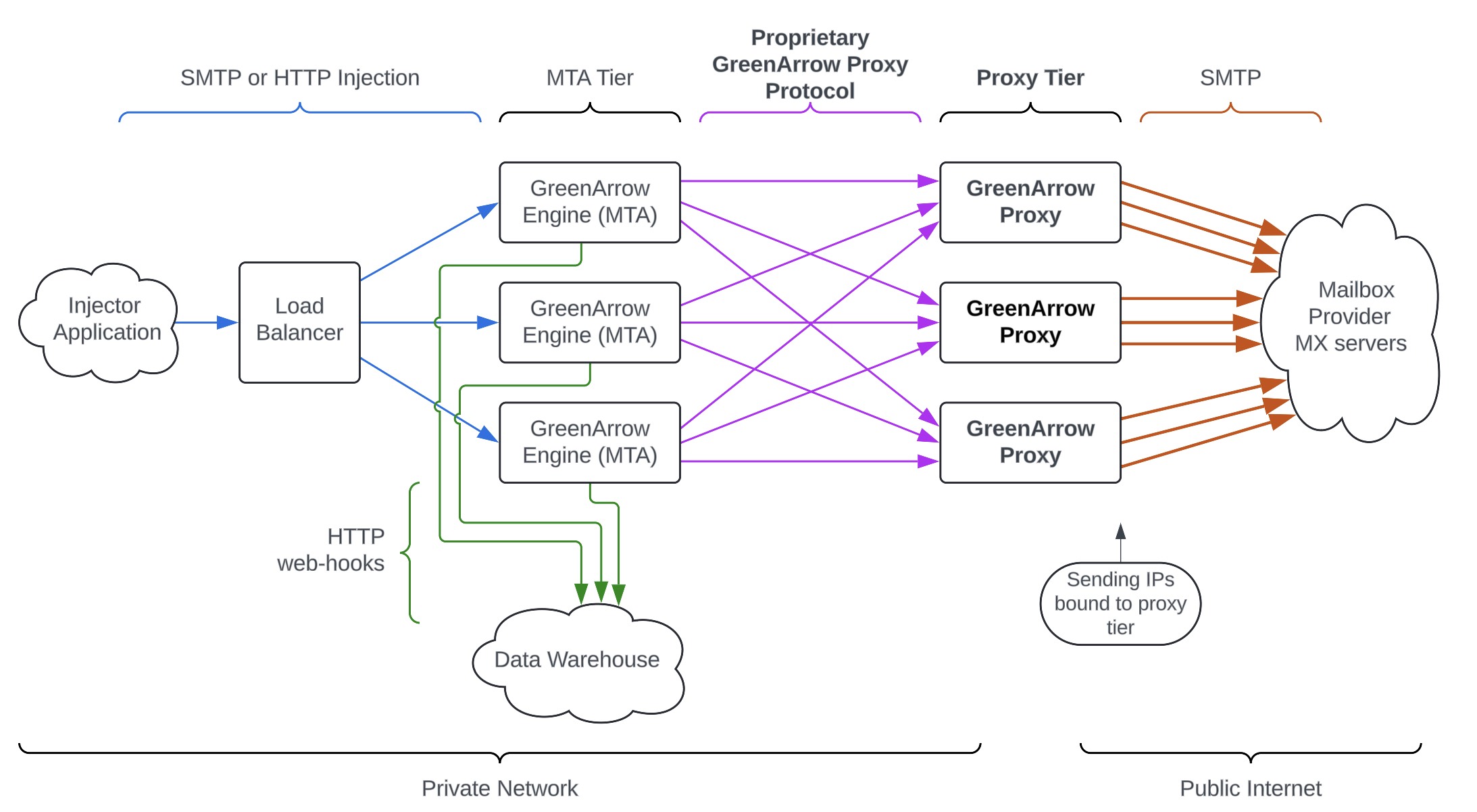
Here are descriptions of parts of the system that are different:
|
MTA Tier
Each server is configured with identical configuration of all of the IP addresses, DKIM keys, and domains. Therefore each MTA is able to handle any outgoing message for any sending IP and any tenant. The configuration files are typically stored in a git repository and published out to all MTAs using software like Puppet, so that a push to git triggers a continuous integration process to publish the config. The MTAs do not directly originate connections to MX Servers. Instead, they connect to the Proxy Tier using the Proprietary GreenArrow Proxy Protocol to request that GreenArrow Proxy originate a connection from the Sending IP (which is bound to the Proxy Server) to the appropriate MX Server. Each GreenArrow MTA leans on GreenArrow Proxy to enforce coordinated cluster-wide throttle limits (maximum messages per hour and maximum concurrent connections). This means that you can configure each MTA with the actual cluster-wide throttle limits that you want. (Configuration from the different MTAs is merged using one of two methods. Average: The cluster-wide limit is the average each MTA’s configured limit for the particular throttle. Sum: The cluster-wide limit is the total of each MTA’s configured limit for the particular throttle. The Sum method is designed to make it easy to transition from using the HAProxy format cluster.) |
|
|
Proprietary GreenArrow Proxy Protocol
The GreenArrow protocol has the following advantages over the HAProxy protocol:
The GreenArrow protocol also handles communication to implement cluster-wide throttling limits.
|
|
|
Proxy Tier / GreenArrow Proxy
This is a set of servers running the GreenArrow Proxy software. Each GreenArrow Proxy server has a subset of the public Sending IPs bound to it. The purpose of this tier is to allow every MTA to make connections from any Sending IP. If the sending IPs were bound to the MTAs, then each MTA would only be able to establish connections from the sending IPs bound to it. Each GreenArrow server also has an IP address on the Private Network, which is used by the MTAs to contact it. These nodes are stateless. GreenArrow Proxy performs the cluster-wide throttle decision making for all deliveries from all IP Addresses that are accessed through that GreenArrow Proxy instance. This provides cluster-wide throttle decision making without introduction any new single-point-of-failure. These servers are sized for high network bandwidth, but do not require much compute or disk IO. A common AWS instance type is |